![]()
Master 2 VMI - TP RF : Convolutionnal Neural Network (CNN)¶
Prérequis pour ce TP : disposer d'un compte Google
- Télécharger ce projet GitHub sur votre machine locale
- Uploader ensuite ce projet dans un dossier lié à votre compte Google Drive
- Ouvrir Google Collab et rechercher votre projet
- Vous pouvez alors exécuter les différentes étapes sucessivement de ce notebook en local sur le serveur Google Collab, ce qui vous évite de disposer d'un GPU en local
La classification¶
La classification est un precessus qui prend une entrée une donnée (par exemple, une image et ses pixels) et qui repond par une decision en sortie (chien, chat, ...) ou la probabiltée de chacune des classes considérées.
Les réseaux de neurones convolutionnels (CNN)¶
Les CNN sont des réseaux profonds composés de différentes couches dans le but d'extraire (d'apprendre) des caractéristiques permettant de différencier les classes traitées.
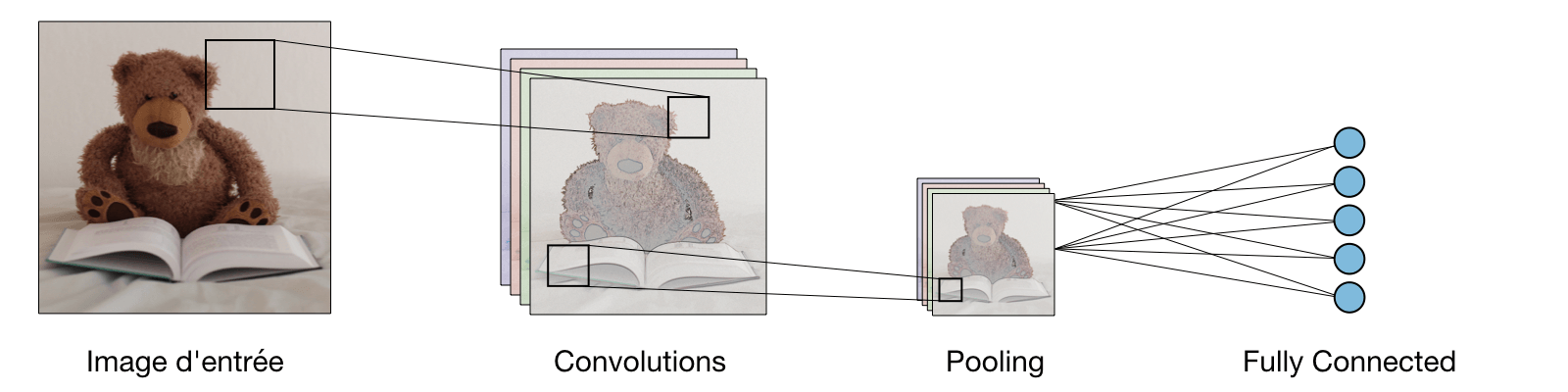
Types de couche¶
Couche de convolution¶
Le principe de la convolution est de glisser un masque sur l'ensemble des pixels de l'image et de calculer le produit de convolution pour chacun des pixels couverts par ce masque.
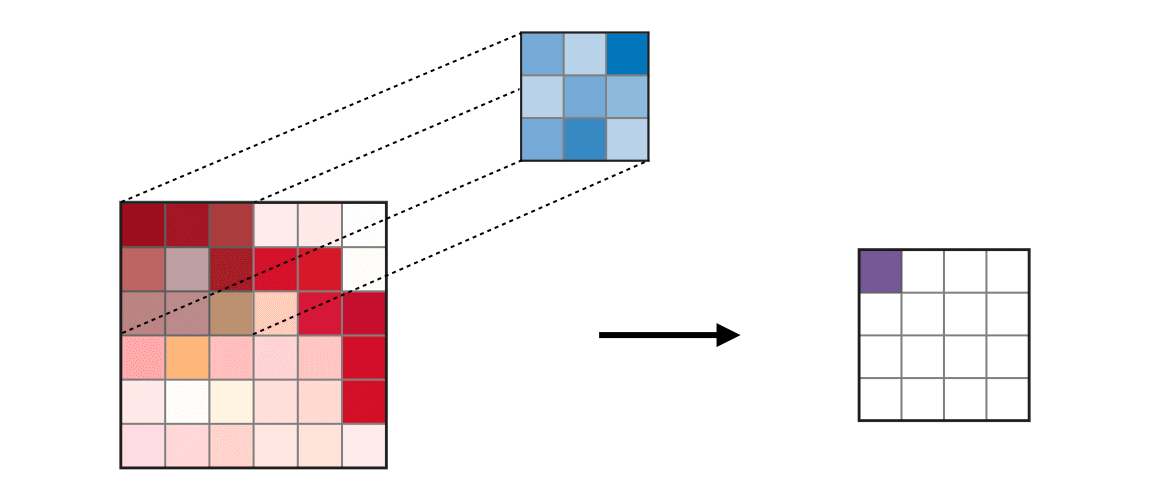 Remarque : l'étape de convolution peut aussi être généralisée dans les cas 1D et 3D.
Remarque : l'étape de convolution peut aussi être généralisée dans les cas 1D et 3D.
Couche de pooling¶
Cette couche a pour but de réduire la dimension spatiale afin de ne garder que les information pertinentes. En particulier, les types de pooling les plus populaires sont le max et l'average pooling.
| Max Pooling | Avreage Pooling | ||
|---|---|---|---|
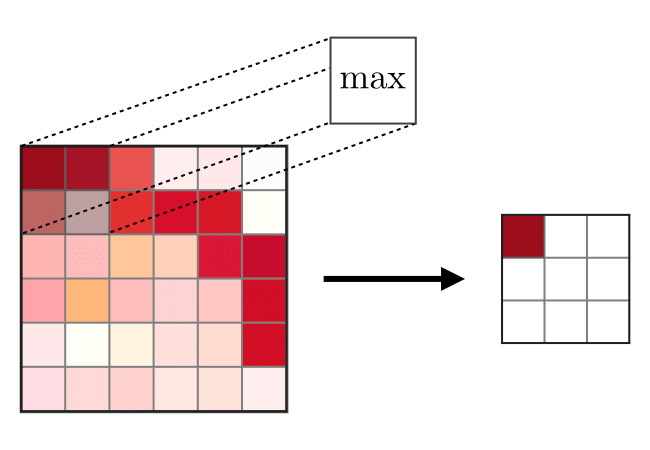 |
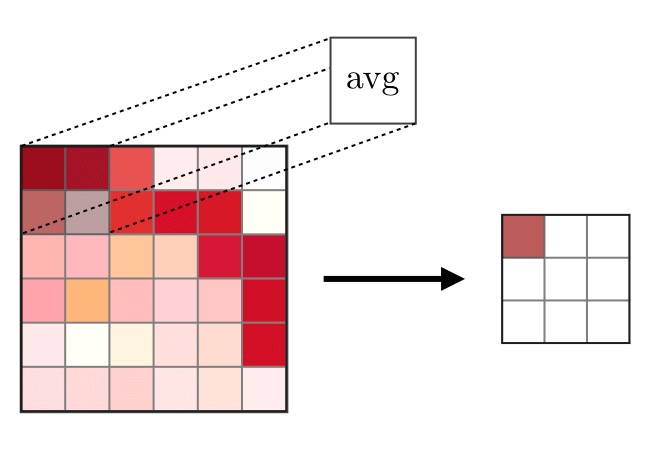 |
CNN pour la classification d'images¶
Dans ce TP, le but est d'utiliser l'approntissage profond pour faire une classification d'images. Pour cela, la necessité d'une base de donnée est indispenssable. Nous allons utiliser ici la base CIFARE10.
CIFARE10¶
CIFAR10 est constituée de 10 classes avec 6000 images dans chaque classe, amenant à 60 000 images au total. Cet ensemble d'images est divisé en 2 sous-ensembles : un ensemble pour l'entraînement qui contient 50 000 images et un ensemble pour le test qui contient 10 000 images.
Les classes de cette base de données sont :
- airplane
- automobile
- bird
- cat
- deer
- dog
- frog
- horse
- ship
- truck
Les images de cette base sont de talle 3x32x32 (des imagettes en couleur RGB).

Chargement de la base¶
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
##########################################################################
# Chargement/telechargement de la base de TRAIN de CIFARE10 #
##########################################################################
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
##########################################################################
# Chargement/telechargement de la base de TEST de CIFARE10 #
##########################################################################
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
##########################################################################
# Definition du module pour parcourir les donnees #
# Paramètres: #
# - Batchsize (nb d'images qui passent en une fois avant retropropagation)#
# - shuffle (ordre de passage aléatoire des images) : #
# Vrai ---> lors de l'entraînement #
# Faux/Vrai ---> lors du test #
# #
# * On va creer 2 modules : un pour le TRAIN et un pour le TEST #
##########################################################################
trainloader = torch.utils.data.DataLoader(trainset, batch_size=16, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=16, shuffle=False, num_workers=2)
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
Visualisation de quelques images de l'ensemble d'entraînement¶
import matplotlib.pyplot as plt
import numpy as np
# functions to show an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
##########################################################################################
# Il faut transposée les images car PyTorch lis les image en [Chanels, Width, Height] #
# et pour les voir il faut qu'elles soient [Width, Height, Chanels] #
##########################################################################################
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# get some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()
# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(16)))

Création d'un CNN simple avec 2 couches de convolutions¶
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=10, kernel_size=5)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels=10, out_channels=20, kernel_size=5)
self.fc1 = nn.Linear(in_features=20 * 5 * 5, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=84)
self.fc3 = nn.Linear(in_features=84, out_features=10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 20 * 5 * 5) #flattening
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
print(net)
Definition de la fonction Loss et de l'optimizeur¶
Exemple ici : Classification Cross-Entropy loss et SGD avec momentum.
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
Entraînement du reseau¶
###############################################
# * Fixer les paramètres de l'entraînement #
###############################################
nb_epoch = 20 # Le nombre d'epoch
loss_list = [] # liste qui va contenir la valeur du loss a chaque epoch
accuracy_list = []
for epoch in range(nb_epoch): # loop over the dataset multiple times
running_loss = 0.0
nb_data = 0.
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs) # Forward
loss = criterion(outputs, labels)
loss.backward() # Backward
optimizer.step() # optimize
# print statistics
running_loss += loss.item()
nb_data += 1.
running_loss = running_loss / nb_data
loss_list.append(running_loss)
correct = 0.
total = 0.
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy_list.append(correct / total)
print("Epoch ", epoch, "; train loss = ", running_loss, "; accuracy = ", correct / total)
torch.save({
'nb_epoch': nb_epoch,
'model' : net.state_dict(),
'listLoss': loss_list,
}, "modelNN.pth")
print('Finished Training and save the model as `modelNN.pth`')
Tracer la courbe du loss¶
plt.subplot(1,2,1)
plt.plot(range(len(loss_list)), loss_list)
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.title("loss curve")
plt.subplot(1,2,2)
plt.plot(range(len(accuracy_list)), accuracy_list)
plt.xlabel("Accuracy")
plt.ylabel("Loss")
plt.title("accuracy curve")
plt.show()

Tester le modèle sur les données de test¶
# Charger un batch de l'ensemble de test
dataiter = iter(testloader)
images, labels = dataiter.next()
# Passer le batch dans le reseau
outputs = net(images)
predicted1 = torch.softmax(outputs.data, 1) #decision probabiliste (floue)
_, predicted2 = torch.max(predicted1, 1) #decision dure (classification)
# print images
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(16)))
print('Predicted: ', ' '.join('%5s' % classes[predicted2[j]] for j in range(16)))

correct = 0.
total = 0.
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %f %%' % ( 100. * correct / total))
Taux de reconnaissance de chacune des classes¶
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %f %%' % (classes[i], 100. * class_correct[i] / class_total[i]))
Exercices - A vous de jouer ...¶
1) Essayer de faire varier le nombre d'epochs pour améliorer la capacité du réseau à discriminer les différentes catégories d'images. Quel est le nombre d'epochs optimal ?
2) Pour ne pas tomber dans un phénomène de sur-apprentissage, modifier le code donné ci-dessus pour intégrer un ensemble de validation qui permet de déterminer les hyper-paramètres du réseau et notamment un nombre d'epochs adapté.
3) Essayer de modifier l'architecture du réseau pour améliorer le taux de reconnaissance de ce dernier. Vous devez faire attention au nombre de filtres utilisés et à la dimension des données de sortie.
4) Proposer une interface permettant de visualiser les sorties des filtres de la première couche.
5) Refaire cet exercice en utilisant un autre réseau comme SqueezeNet déjà pré-entrainé sur ImageNet que vous affiner (fine-tuning) sur les classes de CIFAR10.